
Table of Contents
- Arsitektur LLM: Kekuatan di balik LLM — Transformer
- Aplikasi nyata yang mulai banyak diimplementasikan
- Keunggulan dan Tantangan LLM
- Tren terkini menurut IBM: Skala bukan segalanya
- Contoh Model LLM Populer
- Masa depan menuju Multimodal dan Reasoning
- Kesimpulan: implementasi menuju era AI yang lebih manusiawi
Hai pembaca setia blog dosenidola.com!
Di tengah kemunculan yang luar biasa terkait kecerdasan buatan — Artificial Intelligence (AI), istilah Large Language Model atau LLM semakin sering terdengar. LLM adalah model kecerdasan buatan yang dirancang untuk memahami dan menghasilkan bahasa manusia secara alami —Natural Language (NL). Model ini menjadi tulang punggung berbagai aplikasi populer seperti ChatGPT, Google Gemini, Claude, hingga penulisan kode otomatis.
Arsitektur LLM: Kekuatan di balik LLM — Transformer
Arsitektur Transformer pertama kali diperkenalkan oleh Vaswani et al. dari Google dalam paper berjudul “Attention Is All You Need” yang diterbitkan pada tahun 2017. Paper ini menandai titik balik dalam bidang kecerdasan buatan dan menjadi fondasi bagi perkembangan LLM di masa mendatang.
Keunggulannya? Transformer menghapus mekanisme recurrence seperti RNN/LSTM dan hanya menggunakan mekanisme perhatian (attention), sehingga memungkinkan pelatihan yang lebih cepat dan efisien secara paralel.
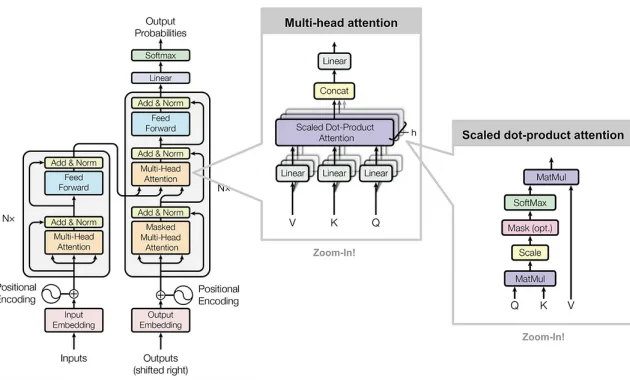
Mekanisme Self‑Attention
Pada intinya, self-attention memungkinkan setiap token (kata atau sub-kata) dalam teks memperhatikan —memfokuskan perhatian (attend)— keseluruhan token lain dalam satu kalimat ataupun konteks yang lebih panjang. Hal ini memungkinkan model untuk memahami hubungan lanjutan antar kata yang tidak berdekatan secara posisi:
- Misalnya dalam kalimat: “Setelah bermain, anak-anak duduk di bangku panjang sambil makan es krim.”
Model bisa langsung memperhatikan kata “bangku”. Dari konteks “duduk”, “panjang”, dan “makan es krim”, maka model tahu bahwa “bangku” berarti kursi panjang, bukan “bangku sekolah” (tingkatan kelas).
Source: https://research.google/blog/transformer-a-novel-neural-network-architecture-for-language-understanding/ - Kemudian, dalam praktiknya digunakan scaled dot‑product attention yang membandingkan query, key, dan value dari token yang sama untuk menghitung bobot (attention weights), lalu memberikan kontribusi sesuai relevansinya.
Multi‑Head Attention & Positional Encoding
- Multi‑Head Attention: attention dilakukan secara paralel oleh beberapa “head” yang mempelajari representasi berbeda dari konteks yang sama. Hasilnya digabung dan ditransformasikan menjadi representasi yang kaya secara semantis.
- Positional Encoding: karena tidak ada urutan eksplisit seperti di RNN, maka Transformer menambahkan informasi posisi token melalui encoding menggunakan fungsi sinus dan cosinus agar urutan tetap dikenali model secara matematis.
Struktur Model: Encoder‑Decoder (Josep Ferrer, 2024)
Arsitektur asli Transformer terdiri dari dua bagian utama:
- Encoder Stack: terdiri dari N lapisan (biasanya 6), masing-masing memiliki self-attention dan lapisan feed-forward (MLP), dengan residual connection dan layer normalization untuk stabilitas pelatihan.
- Decoder Stack: juga terdiri dari N lapisan serupa, tetapi memiliki lapisan tambahan untuk cross-attention terhadap output dari encoder. Decoder juga melakukan masking agar prediksi token bersifat autoregresif (hanya bergantung pada token sebelumnya).
Baca juga:
- 5 Fitur sistem informasi akademik yang dibutuhkan bagi dosen dan mahasiswa
- Masa depan Learning Management System (LMS): Apakah Moodle masih relevan?
Aplikasi nyata yang mulai banyak diimplementasikan
LLM kini digunakan dalam berbagai sektor:
- Customer service: chatbot yang dapat memahami dan merespons keluhan pelanggan.
- Pendidikan: asisten belajar yang menjelaskan konsep dengan berbagai cara.
- Penulisan: alat bantu menulis artikel, laporan, bahkan puisi.
- Pemrograman: alat bantu penulisan kode seperti GitHub Copilot.
Keunggulan dan Tantangan LLM
Keunggulan LLM
1. Multi-tasking
LLM dapat melakukan berbagai tugas — mulai dari menjawab pertanyaan, membuat ringkasan, menerjemahkan bahasa, hingga menulis kode — tanpa perlu pelatihan ulang untuk setiap jenis tugas. Cukup dengan instruksi berbeda, satu model dapat melayani banyak kebutuhan.
2. Zero-shot & Few-shot Learning
Model dapat menyelesaikan tugas tanpa contoh pelatihan khusus (zero-shot), atau hanya dengan sedikit contoh (few-shot). Ini sangat efisien untuk masalah yang belum pernah diajarkan secara eksplisit.
3. Kemampuan Lintas Bahasa dan Budaya
LLM yang dilatih pada data multibahasa memiliki kemampuan lintas budaya dan domain. Ini memungkinkan penggunaan dalam konteks global, bahkan untuk bahasa yang sebelumnya jarang dilatih.
4. Fleksibilitas Aplikasi
LLM dapat diintegrasikan dalam berbagai industri: layanan pelanggan, pendidikan, kesehatan, hukum, pertanian digital, bahkan jurnalistik.
Tantangan LLM
1. Hallucination (halusinasi jawaban)
LLM kadang menghasilkan jawaban yang terdengar benar, tapi keliru secara faktual. Hal ini terjadi karena model tidak “tahu” kebenaran, melainkan hanya memprediksi kata yang paling mungkin muncul.
2. Bias data
Karena dilatih dengan data dari internet yang mungkin bias, model juga bisa menunjukkan bias gender, ras, atau agama. Hal ini dapat berdampak serius jika tidak dikendalikan.
3. Privasi & keamanan
Model berisiko menyimpan atau menghasilkan ulang data sensitif dari set pelatihan, seperti informasi pribadi, dokumen medis, atau isi email.
4. Biaya tinggi & dampak lingkungan
Melatih dan menjalankan LLM skala besar membutuhkan daya komputasi tinggi, yang berarti konsumsi energi besar dan biaya finansial tinggi. Hal ini menimbulkan tantangan keberlanjutan (sustainability) di bidang AI.
Tren terkini menurut IBM: Skala bukan segalanya
Menurut IBM, “semakin besar model tidak selalu berarti semakin baik”. Ada batas di mana penambahan parameter tidak sebanding dengan peningkatan kinerja. IBM menekankan pentingnya:
- Reliabilitas: LLM harus dapat diandalkan di konteks kritis.
- LLMOps: sistem operasional untuk mengelola LLM secara efisien, mirip dengan DevOps pada pengembangan perangkat lunak.
- Adaptasi bisnis: LLM harus relevan dan efektif untuk kebutuhan dunia nyata.
Banyak orang mengira bahwa semakin besar Large Language Model (LLM), maka semakin cerdas dan akurat hasilnya. Namun menurut IBM, asumsi ini tidak sepenuhnya benar. Dalam beberapa studi, ditemukan bahwa model yang lebih besar memang memiliki kapasitas yang lebih tinggi, tetapi juga membawa sejumlah risiko, terutama dalam hal keandalan. Salah satu temuan penting adalah semakin besar model, semakin besar pula kemungkinan terjadinya hallucination —yaitu keluaran yang terlihat meyakinkan, namun sebenarnya salah secara faktual. Hal ini menjadi persoalan serius terutama dalam konteks kritis seperti hukum, kesehatan, atau bisnis, di mana kesalahan informasi bisa berakibat fatal.
Selain itu, performa LLM yang sangat besar justru bisa menurun dalam konteks yang sangat spesifik. Model yang terlalu umum kadang gagal memahami nuansa domain tertentu. Sebaliknya, model yang lebih kecil tetapi di-fine-tune dengan baik justru dapat menghasilkan respons yang lebih relevan dan akurat sesuai kebutuhan. Hal ini menandakan bahwa besarnya model bukan satu-satunya indikator kualitas.
Dari sisi operasional, efisiensi menjadi isu utama. Menjalankan model berskala besar membutuhkan sumber daya komputasi yang sangat mahal, baik dari segi perangkat keras maupun energi. Oleh karena itu, banyak organisasi mulai mempertimbangkan model yang lebih kecil dan terfokus (compact dan domain-specific) untuk menyeimbangkan antara biaya dan kinerja.
Sebagai solusi, IBM merekomendasikan pendekatan yang disebut right-sizing, yakni memilih model dengan ukuran yang “cukup” —tidak harus besar— namun sesuai dengan kompleksitas tugas. Model seperti ini lebih ringan, lebih cepat, dan lebih mudah dikendalikan, tanpa mengorbankan akurasi dalam konteks yang tepat.
Contoh Model LLM Populer
| Nama Model | Pengembang | Jumlah Parameter | Status |
| GPT-4 | OpenAI | >1 triliun* (perkiraan) | Komersial |
| Claude | Anthropic | Tidak diumumkan | Komersial |
| PaLM 2 | Google DeepMind | Tidak diumumkan | Komersial |
| BLOOM | BigScience | 176 miliar | Open-source |
| LLaMA 2 | Meta AI | 7–70 miliar | Open-source |
| DeepSeek R1 | DeepSeek | 671 miliar | Open-source |
Keterangan:
- Komersial: Model hanya bisa diakses lewat produk tertentu (seperti ChatGPT atau Gemini), dan pengguna tidak dapat melihat atau mengubah parameternya.
- Open-source / Open-weight: Model dibagikan ke publik, sehingga pengembang, peneliti, atau universitas bisa mempelajarinya, melatih ulang, bahkan membangun versi modifikasi.
Masa depan menuju Multimodal dan Reasoning
Jika LLM hari ini sudah terasa canggih, masa depannya jauh lebih menakjubkan. Kita sedang bergerak menuju era Multimodal LLM (MLLM) —tidak hanya memahami teks, tapi juga mampu “melihat” gambar, “mendengar” suara, bahkan “merasakan” video. Dengan kata lain, LLM tidak lagi terbatas pada satu jenis input, tapi mampu memahami berbagai bentuk informasi seperti manusia.
Bayangkan seorang dokter virtual yang bisa membaca laporan medis, menganalisis gambar CT scan, dan sekaligus mendengar keluhan pasien. Atau asisten belajar AI yang bisa menjelaskan soal matematika dari gambar tulisan tangan anak, lalu membacakan penjelasannya secara lisan. Semua ini menjadi mungkin berkat perkembangan LLM menuju multimodalitas.
Namun multimodalitas hanyalah satu sisi. LLM juga semakin dilatih untuk reasoning —kemampuan bernalar logis, menyimpulkan informasi tersembunyi, dan menjawab pertanyaan kompleks yang membutuhkan lebih dari sekadar cocok-mencocokkan pola kata. Kita akan menyaksikan model AI yang bisa menalar sebab-akibat, menjawab “mengapa” dan “bagaimana” secara lebih masuk akal, bukan hanya “apa”.
Selain itu, perusahaan seperti OpenAI dan Anthropic juga mulai menanamkan prinsip AI alignment — agar model tidak hanya pintar, tapi juga selaras dengan nilai-nilai manusia. Tujuannya? Menghindari jawaban yang bias, menyesatkan, atau membahayakan. Dengan pendekatan ini, LLM ke depan akan makin aman digunakan dalam bidang sensitif seperti pendidikan, hukum, kesehatan, dan pemerintahan.
Kesimpulan: implementasi menuju era AI yang lebih manusiawi
Perkembangan LLM tidak berhenti pada “lebih besar dan lebih cepat”, melainkan lebih manusiawi, kontekstual, dan terintegrasi dalam kehidupan kita. Dari menulis hingga melihat, dari menjawab hingga menalar —LLM masa depan akan menjadi “rekan kerja” yang lebih cerdas, empatik, dan bertanggung jawab.



1 comment